API
在网络爬虫的世界里,你可以通过爬取html页面上的信息来收集信息,而使用开放的API接口是另一种方式。
这里开放的API接口指的是:服务器可访问的http请求。其实html中的数据也是通过访问http请求获得的,但是这里是直接利用请求返回的数据。
为何是可访问的?因为对于http请求,服务器或许是要做验证的,一般的post的请求必须做验证,get请求相对放宽限制。
google API
对于API方面的开放,业界没有一家企业做的比google还好了,而且大部分都是免费的,只是每个月需要限制访问的流量。对于API的访问,google是有做校验的,需要相应接口的key,读者可以按照以下的步骤获取(但是首先你必须可以翻墙):
这里以google的maps接口为例,如下图搜索maps,需要地图相关的API: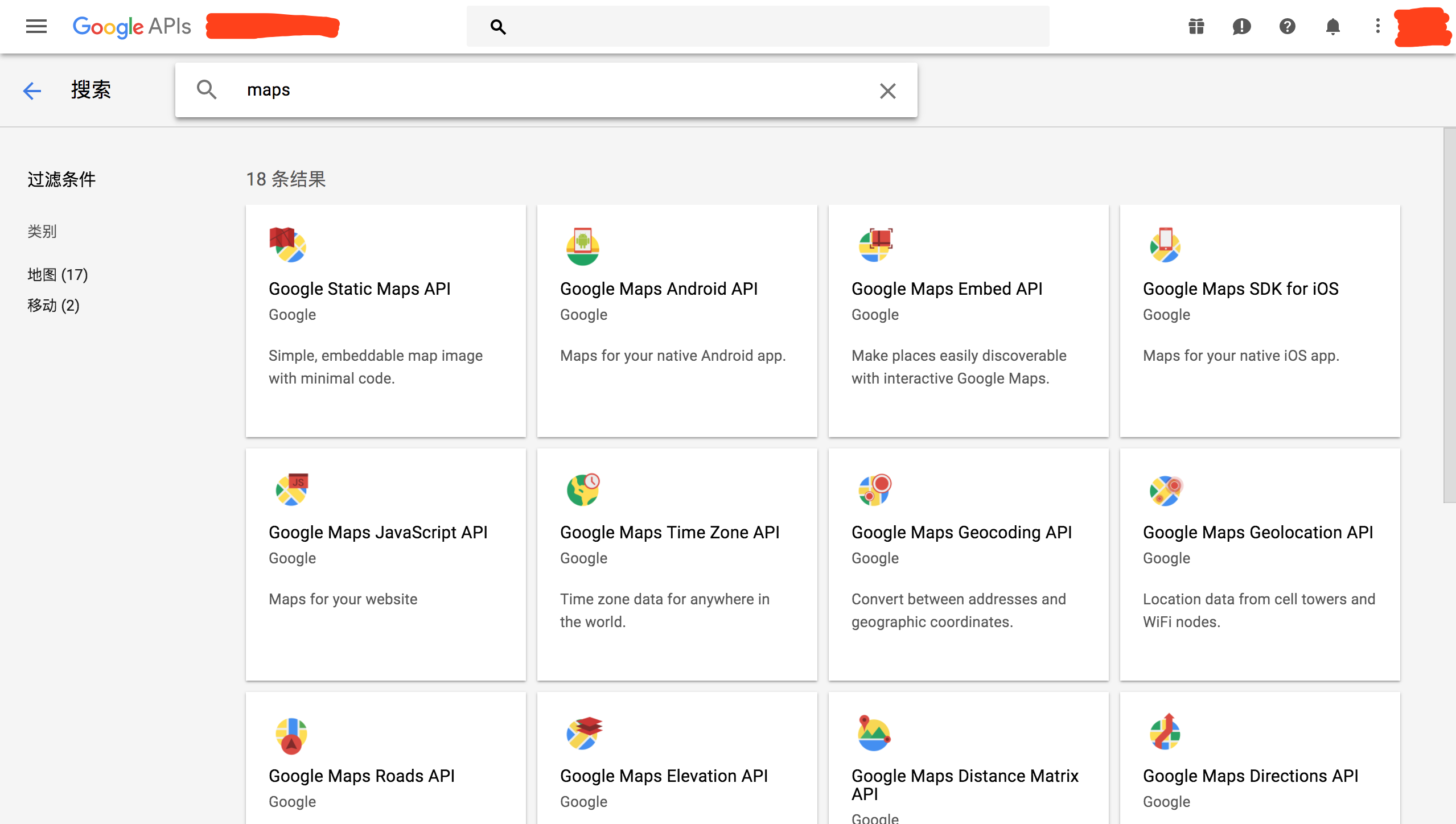
你可以通过点击API和服务中的库跳转到上图界面: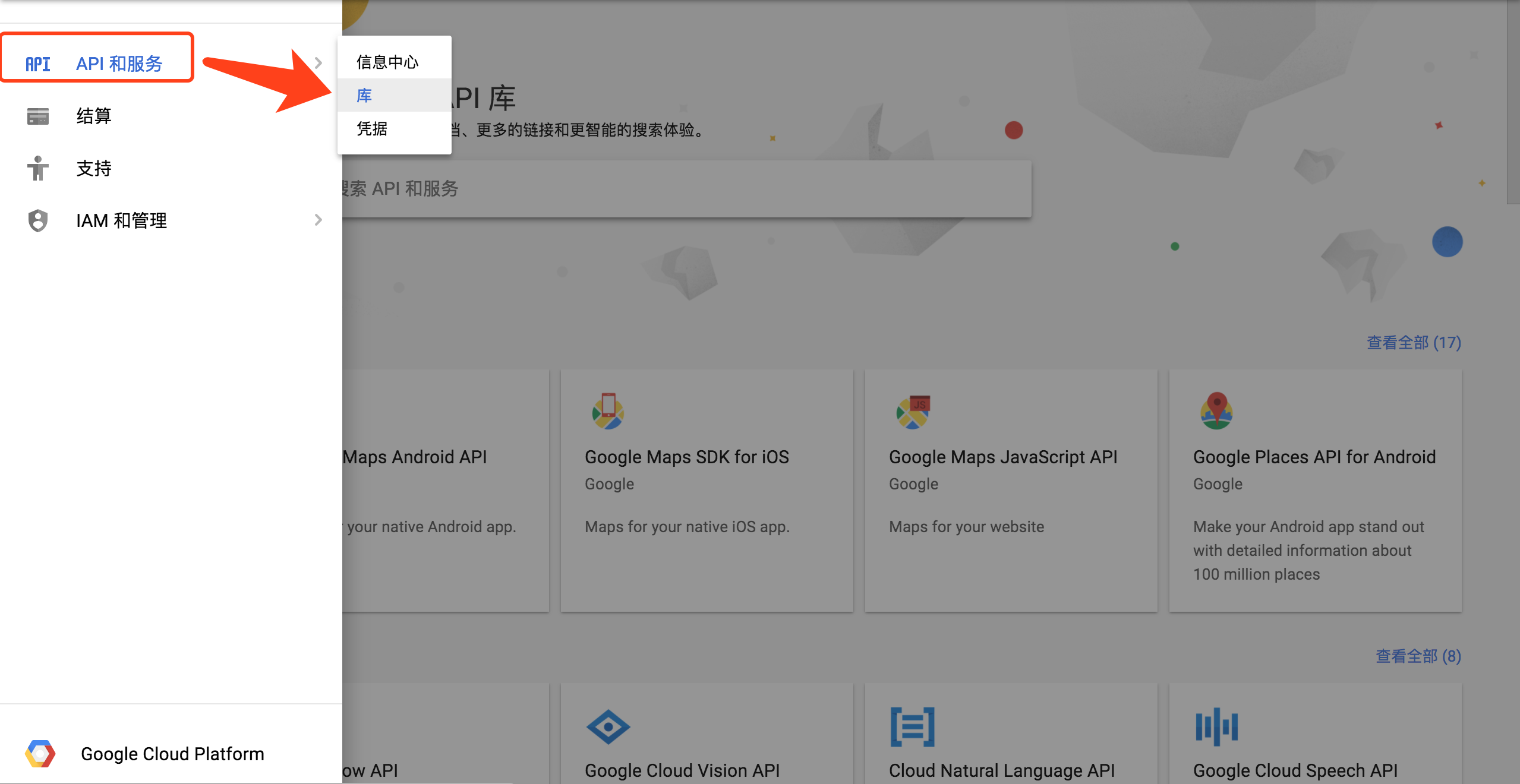
google中你可以在信息中心界面查看你API访问的情况: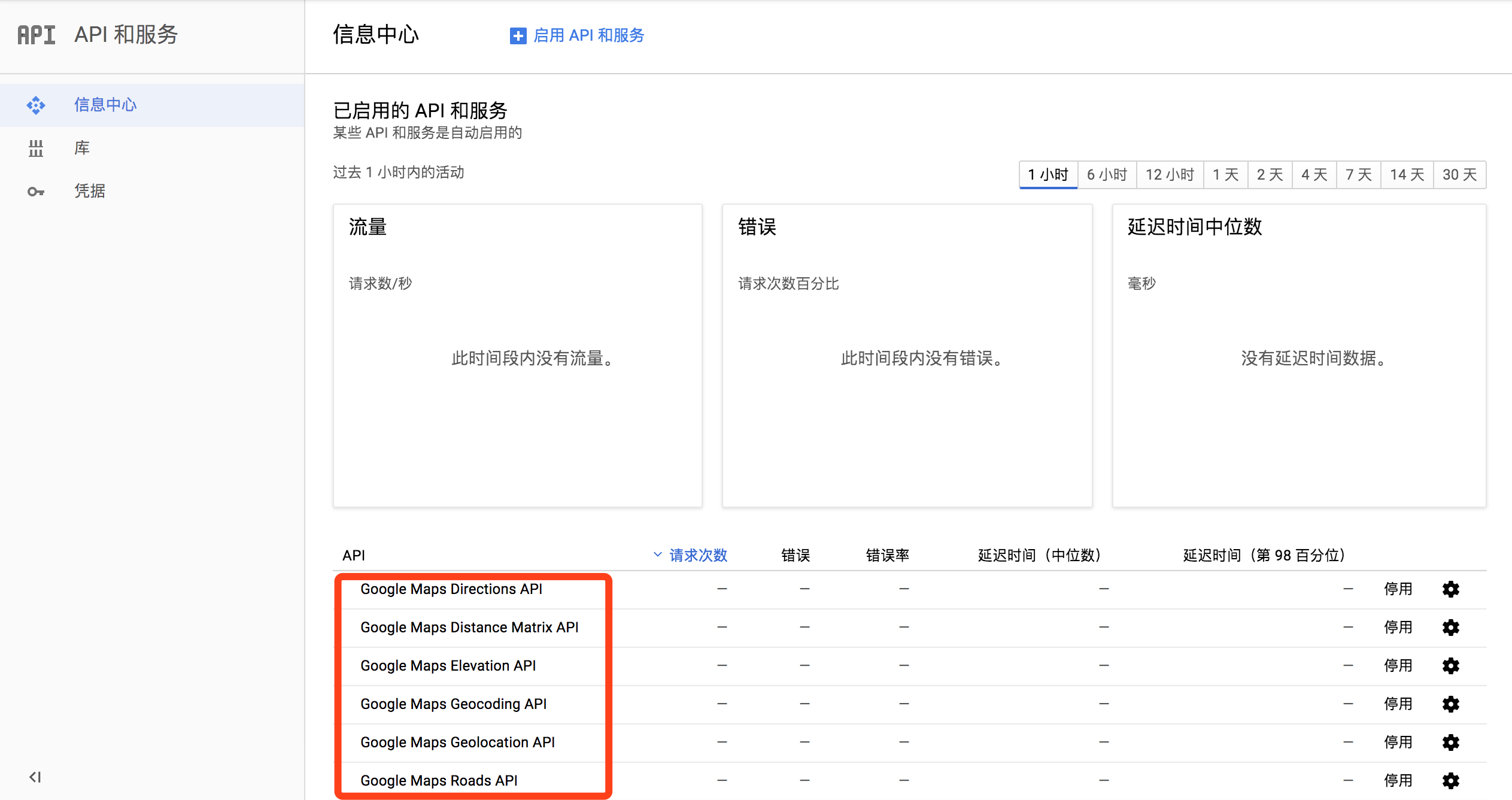
对于访问时需要的key可以在凭证中查看: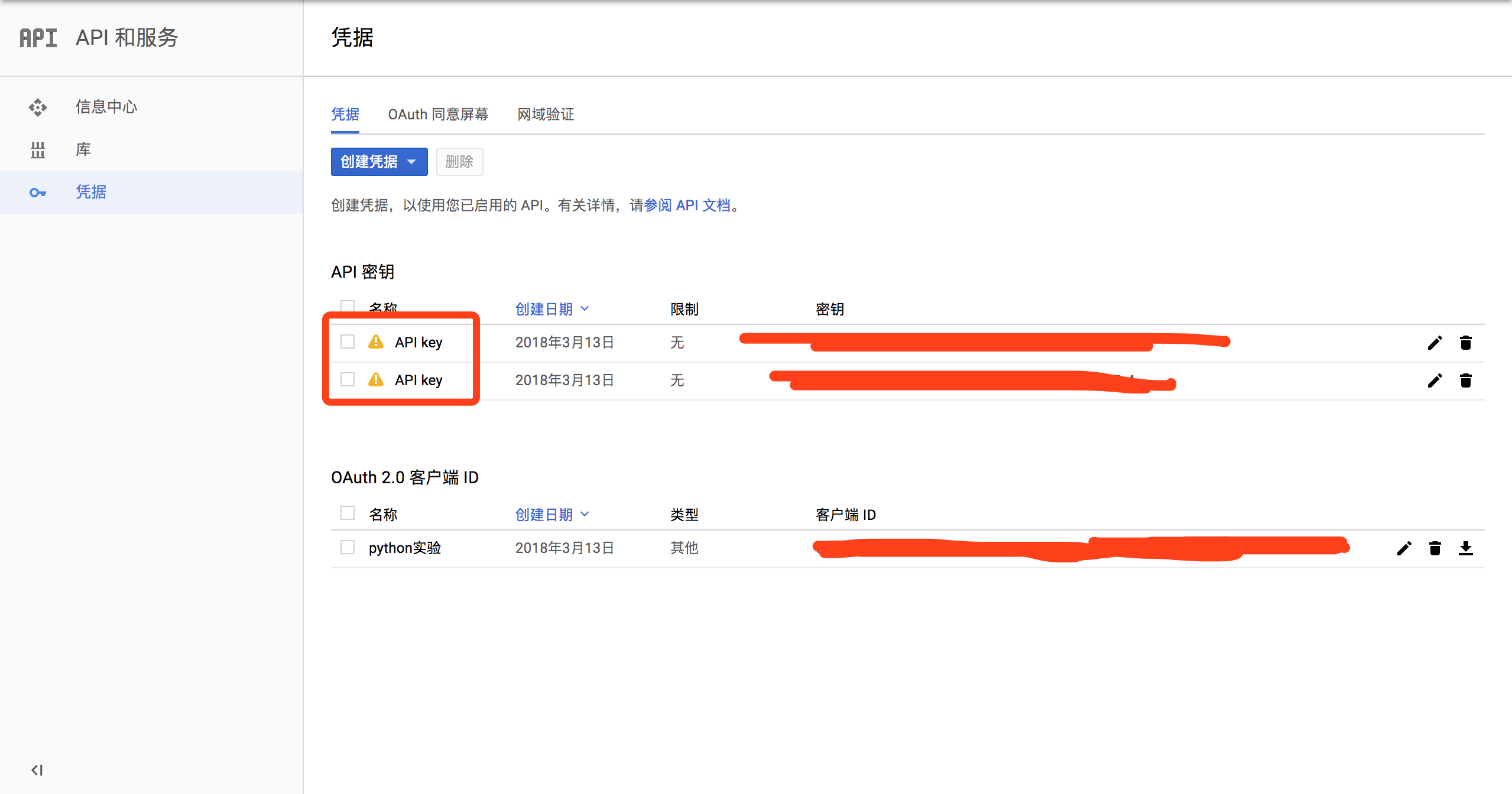
然后你就可以使用key来通过API获取信息了:1
2
3
4
5
6
7
8
9比如:
# 将街道解析成经纬度
https://maps.googleapis.com/maps/api/geocode/json?address=1+Science+Park+Boston+MA+02114&key=<你的API key>
# 用 Time zone(时区)API 获取任意经纬度的时区信息
https://maps.googleapis.com/maps/api/timezone/json?location=42.3677994,-71.0708078×tamp=1412649030&key=<你的 API key>
# 用地点经纬度获取对应的海拔高度
https://maps.googleapis.com/maps/api/elevation/json?locations=42.3677994,-71.0708078&key=<你的 API key>
解析json
如果使用http访问的API接口,你必然会遇到解析json的问题。python中可以使用自带的json包进行解析。
这里以 http://freegeoip.net/json/ 为例,来获取ip地址对应的城市:1
2
3
4
5
6
7
8
9
10import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get("country_code")
print(getCountry("121.97.110.145"))
对于一些多重复杂的json表达式,loads方法将其解析为key-value的形式:1
2
3
4
5
6
7jsonString = '{"arrayOfNums":[{"number":0},{"number":1},{"number":2}], "arrayOfFruits":' \
'[{"fruit":"apple"},{"fruit":"banana"},{"fruit":"pear"}]}'
jsonObj = json.loads(jsonString)
print(jsonObj.get("arrayOfNums"))
print(jsonObj.get("arrayOfNums")[1])
print(jsonObj.get("arrayOfNums")[1].get("number")+jsonObj.get("arrayOfNums")[2].get("number"))
print(jsonObj.get("arrayOfFruits")[2].get("fruit"))
wiki百科实践
这里我们仍然以wiki作为例子,在wiki百科的历史编辑区中,会记录编辑人员的ip地址,我们用上面的方法再加上网页跳转的形式,来获取相关的地区信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56#! /usr/local/bin/python3
# encoding:utf-8
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import json
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org" + articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
return bsObj.find("div", {"id": "bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
def getHistoryIPs(pageUrl):
# Format of history pages is: http://en.wikipedia.org/w/index.php?title=Title_in_URL&action=history
pageUrl = pageUrl.replace("/wiki/", "")
historyUrl = "http://en.wikipedia.org/w/index.php?title="+pageUrl+"&action=history"
print("history url is: " + historyUrl)
html = urlopen(historyUrl)
bsObj = BeautifulSoup(html, "html.parser")
# finds only the links with class "mw-anonuserlink" which has IP addresses instead of usernames
ipAddresses = bsObj.findAll("a", {"class": "mw-anonuserlink"})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
def getCountry(ipAddress):
try:
response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get("country_code")
links = getLinks("/wiki/Python_(programming_language)")
while(len(links) > 0):
for link in links:
print("-------------------")
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
country = getCountry(historyIP)
if country is not None:
print(historyIP+" is from " + country)
newLink = links[random.randint(0, len(links)-1)].attrs["href"]
links = getLinks(newLink)
其实上面的方法再前面的章节中已经提及过,现在增加的只是将html上爬取的信息,再通过API的加工得到最终的信息。只是想要告诉大家,爬虫不只是解析html那么简单。