什么是回表
在mysql——索引(一)中我们知道了索引的数据结构是B+树,要描述回表的过程,还得提前了解索引的数据结构。还是以索引(一)中的例子为例,假设,我们有一个主键列为id的表,表中有字段k,并且在k上有索引,建表语句如下:1
2
3
4
5mysql> create table t(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中row1~row5的(id,k)值仍然为(100,1)、(200,2)、(300,3)、(500,5)和(600,6)
则基于主键索引和k值索引的结构图如下: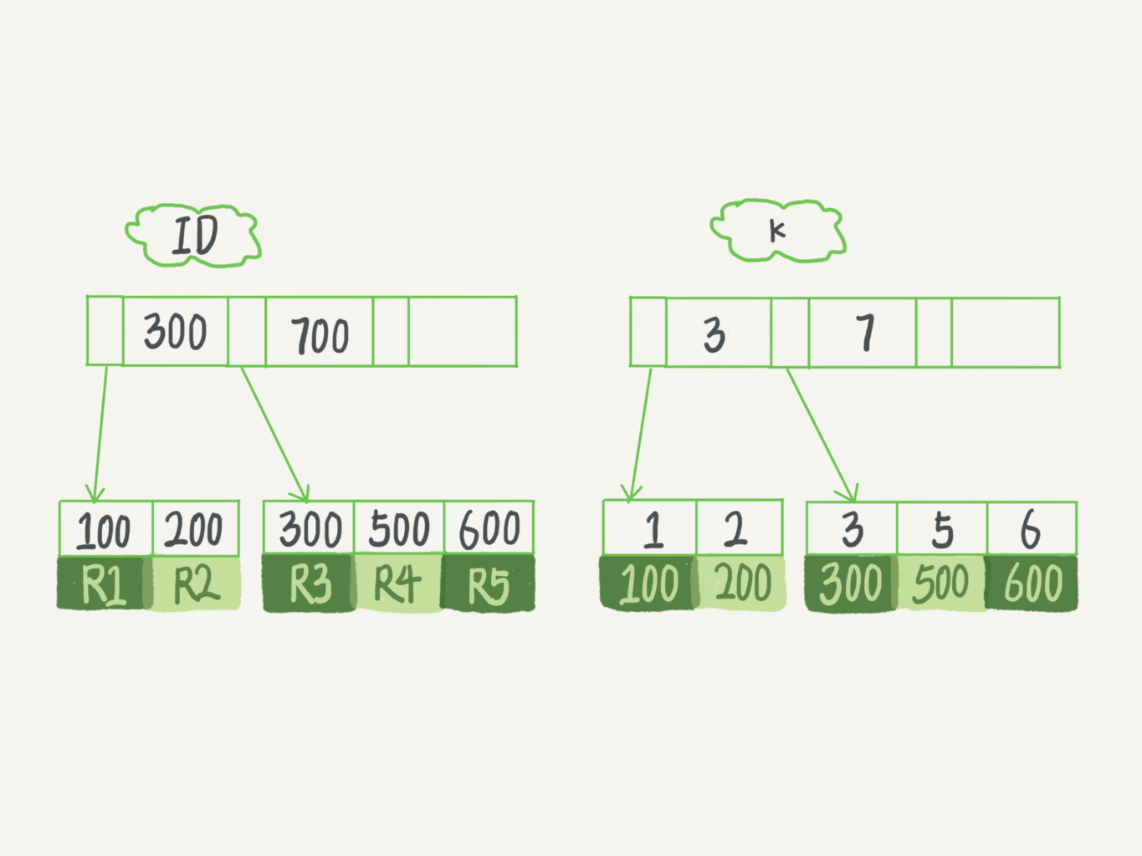
回答什么是回表之前,我们来讨论一个问题:基于主键索引的查询和普通索引(此处是k值索引)的查询有什么区别?
- 方式一:执行select * from t where id = 500,即为主键查询,则只需要搜索主键id这棵B+树。
- 方式二:执行select * from t where k = 5,即为普通索引查询,则先需要搜索k值B+树,得到id=500,再搜索主键id这颗B+树。
方式二中先到普通索引进行搜索获取主键id后,仍需要回到主键id这棵B+树进行搜索获取数据的行为就是回表。
为什么搜索完k值树后还要回主键id树呢?因为前面我们已经知道了:只有主键索引的叶子节点上存储了全量的数据,普通索引叶子节点上存储的是主键id。所以一般建议使用主键id查询效率会更高一些,毕竟少了回表的过程。
索引覆盖
从上面描述我们知道:回表会影响查询的性能。
如果将方式二的语句改写成:select id from t where k = 5,还需要进行回表吗?
这里的答案是:不需要进行回表。因为k值搜索树中存储的是主键id,已经覆盖了查询所需的数据。
我们再将上面的sql改写成以下3中方式,判断一下是否需要回表?
- select id, k from t where k = 5;
- select k, name from t where k = 5;
- select id, name from t where k = 5;
从索引覆盖的角度出发,第一种方式是不需要进行回表的,后面两种方式仍然需要回表,因为k值搜索树中只有k和id,并没有name数据。
索引覆盖:如果查询所需的数据在非主键索引中已经可以满足,就不用再回到主键id搜索树中获取额外数据。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
最左前缀原则
有索引的查询就可以防止全表扫描,所以理论上每一种查询都建立一个索引是最保险的。如果真的为每一种查询都设计一个索引,索引是不是太多了?
实际上并不用为每一种查询设计索引,因为B+树这种索引结构,可以利用索引的“最左前缀”来定位记录。只要调整成合理的顺序,一个索引是可以应用在多种业务查询上的。
为了直观地说明这个概念,我们用(a,b)这个联合索引来进行分析。假设,我们有一个表t1,表中有业务字段(a,b,c),并且在(a,b)上有联合索引:1
2
3
4
5
6
7
8CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`a` varchar(64) DEFAULT NULL,
`b` varchar(64) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
INDEX `idx_a_b` (`a`,`b`)
) ENGINE=InnoDB;
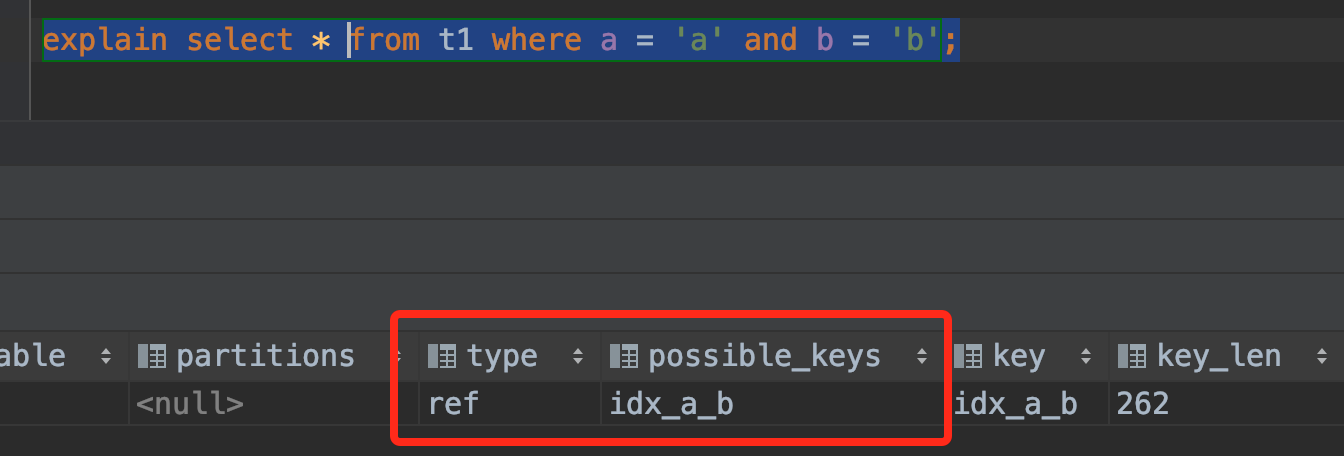
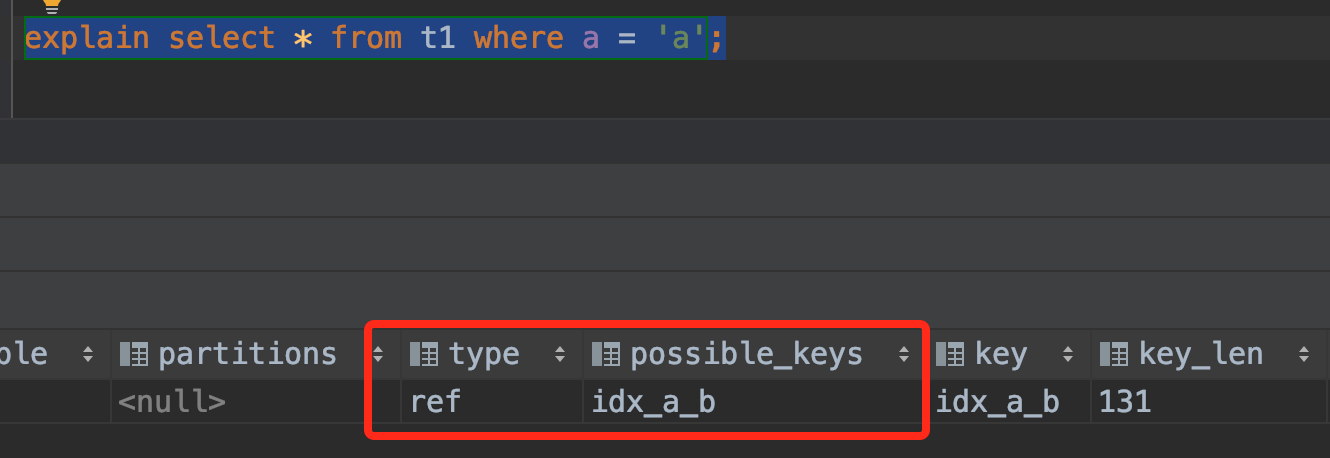
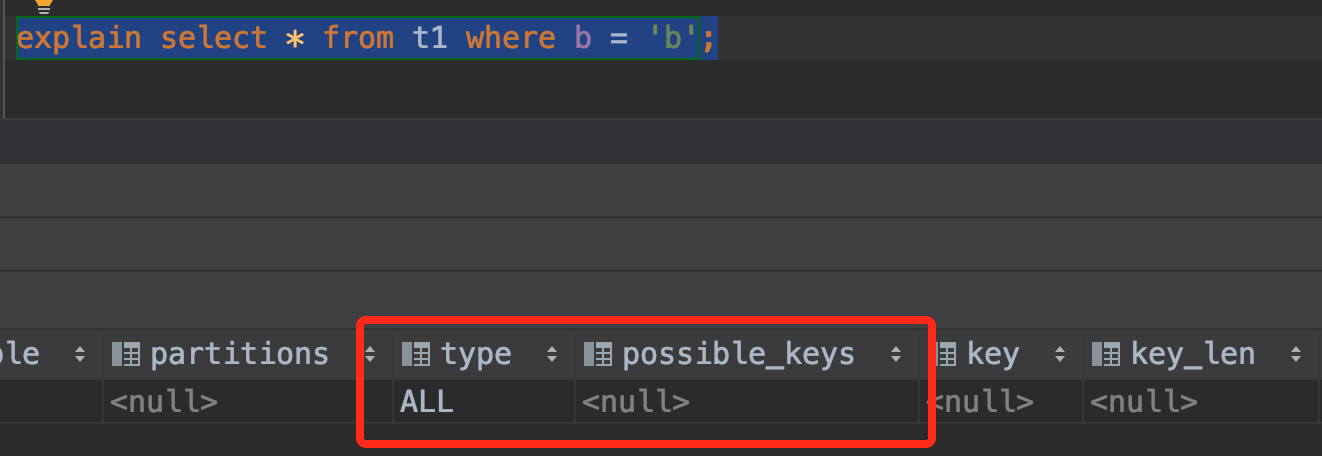
这里我们使用explain命令来分析不同的条件查询是否有使用到索引。
下面贴出explain执行的5种条件查询以及分析结果:
- 使用a和b联合查询
- 使用a等值查询
- 使用b等值查询
- 使用c等值查询
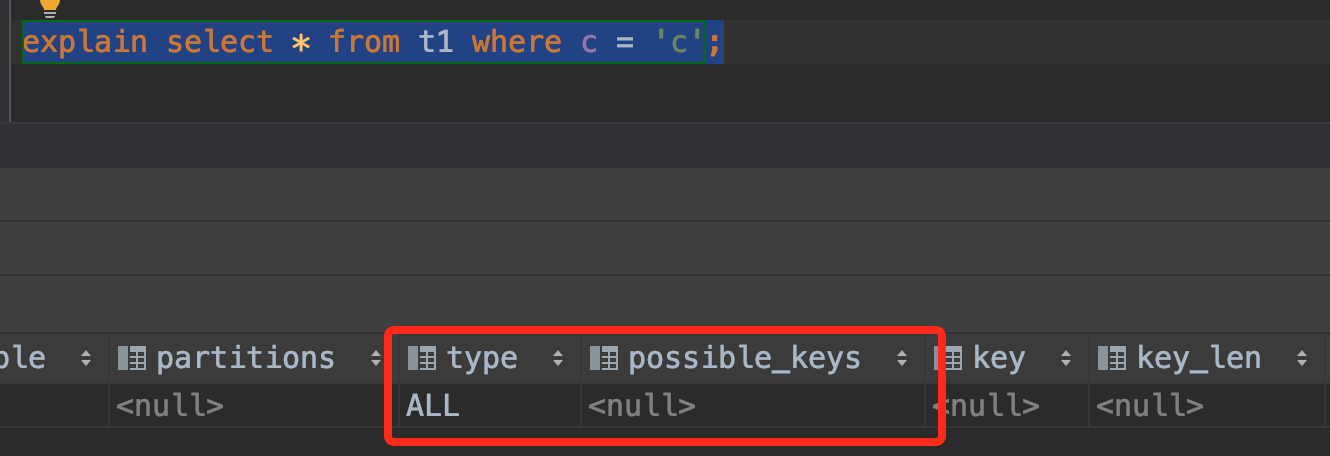
- 使用a模糊查询
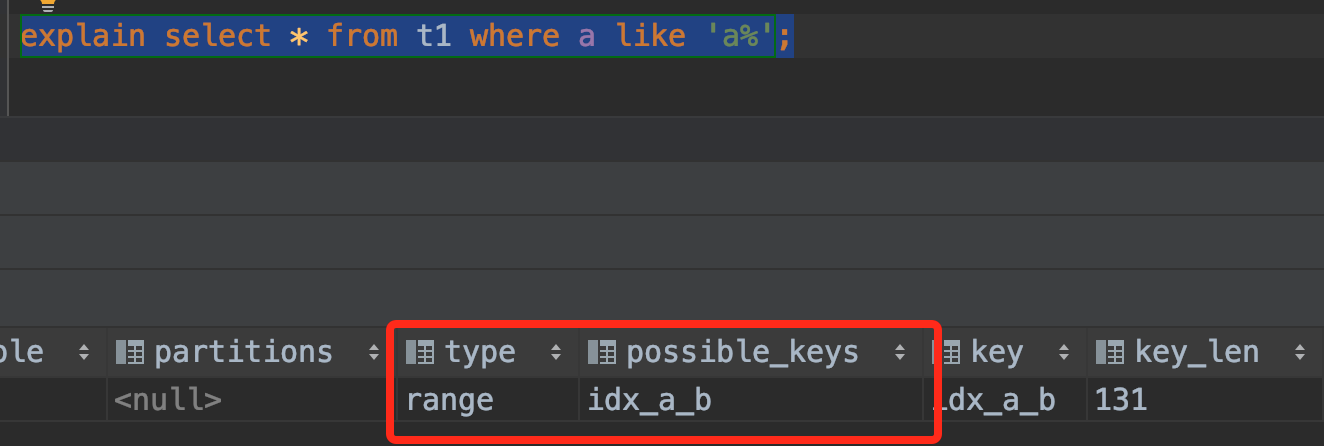
从以上的结果可知:最左前缀原则,既可以作用于联合索引的最左N个字段,也可以作用于字符串索引的最左M个字符。
如果将t1表看作一张业务表,那么很明显,根据字段a和b的联合查询以及单独根据字段a的查询一定是高频业务。这里就涉及到一个问题:在建立联合索引的时候,如何安排索引内的字段顺序?
利用索引的最左前缀原则,我们可以制定如下标准:根据业务优先考虑索引的复用,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。比如上面的例子,在得知字段a查询比字段b高频,所以将a放在联合索引前面,这样不用在给字段a单独建立索引。
索引下推
对于联合索引的查询,mysql还引入了索引下推的优化,减少回表。(这里版本要>=MySQL 5.6)
还是以表t1举例,有这样的业务查询:select * from t1 where a like ‘a%’ and b = ‘b’;
如果是小于MySQL 5.6的版本是这样处理的:
1.从ab联合搜索树中找到第一个以a开头的元素存储的id的值。
2.拿这个id去主键id搜索树中获取数据,并再根据后续条件进行筛选。
3.重复第一步,直到不符合 a like ‘a%’为止。
如果是MySQL 5.6及以上版本会将这个过程优化:
1.从ab联合搜索树中找到第一个以a开头的元素,并将条件b下推,直接进行筛选。
2.重复第一步,直到不符合 a like ‘a%’为止。
假设t1表中存在大量字段a以a开头但是字段b!=’b’的数据,则需要进行大量回表。如果有了索引的下推,在ab联合搜索树中我们直接可以判断后续条件,不用进行任何的回表操作。
小结
今天在索引数据结构的基础上,阐述了什么是回表,然后以减少回表为出发点,讲了索引覆盖和索引下推两种优化(前者是业务优化,后者是数据库自身优化)。中间还插入了索引的最左前缀原则以及建立索引的原则。